Physical Reality of the Sovereign AI Gap

TL;DR
The global buildout of city-sized AI infrastructure in 2026 has introduced a fundamental shift in the cybersecurity landscape. As high-value, trillion-parameter models move into multi-tenant cloud environments, the traditional "logical" boundaries of software security are being bypassed by the inescapable physics of the hardware itself. This essay examines the emergence of side-channel vulnerabilities and the novel hardware-driven standards required to protect sovereign AI interests.
A critical aspect of technology in 2026 is artificial intelligence infrastructure, a phrase that evokes images of sprawling datacenters as large as cities, filled with server racks populated to the brim with humming hardware like high-rise housing for GPUs. Like a small city, it receives electricity and fresh water. Popular discourse around this topic circulates around how the demand for these utilities drives up the cost of living in rural communities. Another popular topic discusses how much of the existing and upcoming infrastructure is driven by and financed by a relatively small number of large corporations: Oracle, Google, Amazon, Microsoft, Meta. Everyone wants the best hardware for AI training, something Nvidia specializes in with their latest GPU product line. One topic of growing interest relates to data security and integrity, certainly not a new concern but one that is evolving as IT and AI become synonymous in the context of infrastructure.
Before AI, data security and integrity concerns drove cloud computing regulations and compliance requirements. For example, US government contractors are required to use cloud service providers (CSPs) with a FedRAMP authorization-to-operate (ATO). This ensures that government contract data, such as controlled unclassified information (CUI), is adequately protected by an external provider, i.e., not the contractor but the cloud service provider. For most of the supply chain, this means unclassified data is stored, processed, and transmitted using information systems that reside within the US and comply with the strict NIST SP 800-53 security requirements. A FedRAMP-compliant CSP can have multiple customers as the 800-53 requirements–including logical separation, encryption, access control, and information flow control–provide separation between multiple tenants within the same infrastructure. This means that a company with a FedRAMP ATO is green-lit to be used by a government contractor, provided the contractor takes adequate steps to address compliance requirements that fall outside the CSP’s scope. In other words, multi-tenancy starts to make sense thanks to compliance requirements.
With AI, the picture becomes a bit more complicated, and for a number of reasons. As stated earlier, the lion’s share of infrastructure is built and supported by a few large corporations, primarily (though certainly not exclusively) based in the US. Complex machine learning architectures, now entering the trillion-parameter scale, are designed, trained, and deployed as proprietary products. Hardware and software are not only intellectual property but also export controlled for national security reasons. Access to the most powerful computation infrastructure becomes dependent on compliance with US regulations and policies, some of which 2025 proved to be subject to the whims of the White House. Anyone who wants to operate independently, whether a private company or a foreign nation, needs “sovereign AI,” infrastructure that they own and operate.
India is a perfect example of a nation that refuses to be dependent on the US despite sharing a common rival in China. India famously declined to purchase the F-35, primarily because of the inevitable dependence on Lockheed Martin for maintenance and updates. If US-India relations were to sour (such as when Trump lied about his involvement with the India-Pakistan ceasefire), then critical support would become geopolitical leverage. The same is true for AI infrastructure, though maybe even riskier than a fighter jet since AI spans and supports many industries. India now prioritizes homegrown AI infrastructure and model development to address needs in healthcare, manufacturing, agriculture, education, and more. This can be a real game changer, not merely by virtue of the myriad AI applications soon to come from the densely populated subcontinent, but also by validating the concept of sovereign AI at geopolitical scales.
It’s likely that the bulk of India’s AI implementation will come from commoditized models that don’t require the performance or cost demanded by frontier models. After all, frontier models like those by OpenAI and Google require billions of dollars to train on the latest and greatest Nvidia hardware. But these are intended to be general use models, developed by companies with the nominal goal of artificial general intelligence. For most use cases, it would be better to take a lower tier model, train it on a curated dataset (for example, agricultural data), and deploy it in a number of applications focused on a niche market. The resulting specialist AI couldn’t compete directly with Gemini or Claude, but it might be good enough to turn AI investment into profit. Does that mean India has no use case for frontier models? Not necessarily, as the advanced reasoning of these models potentially offers competitive edges in areas where general intelligence is useful like R&D and strategy. It might even prove cost-effective in the long term to pay for a closed, fully trained frontier model in the short term if it helps accelerate the development of fine-tuned commoditized models. Either way, whether deploying applications that use closed models owned by a foreign company or open models owned domestically, operational scale AI infrastructure will necessarily involve multi-tenancy.
Be they sovereign nations or multinational corporations, infrastructure owners must manage multi-tenancy risks. The existing regulatory and compliance frameworks such as FedRAMP and CMMC were designed with cloud computing in mind, as businesses of all sizes began relationships with the major cloud providers to transfer IT maintenance, configuration, and security. The main three players in this space continue to be AWS, Microsoft, and Google, with other companies offering more specialized products and services. Some companies even use multiple cloud services and a cloud access security broker to manage security risks more effectively. As mentioned earlier, the customer is generally responsible for security controls; even when a control implementation is fully inherited by the cloud provider (e.g., physical security at the offsite backup location), the customer still needs to document this inheritance. This way, the company has clearly defined which controls it is responsible for, which controls the CSP is responsible for, and which controls are shared between the two parties, typically defined in a customer responsibility matrix or service level agreement. Just as a company’s system security plan (SSP) might define how the engineering department is logically separated from the finance department, a CSP’s SSP might define how two tenants’ resources are logically separated. This controls the risk of sharing information systems among multiple tenants, and it also establishes that the CSP is responsible if a faulty implementation leads to data security and integrity issues.
How does this change with AI? Well, NIST has some changes in the works, including SP 800-218A, which adds AI-specific information for the software development lifecycle, an AI Risk Management Framework, a taxonomy of machine learning attacks and mitigations, and a control overlay for SP 800-53 to support a Cybersecurity Framework Profile for AI. For use cases of adapting and using generative AI, using and tuning predictive AI, using single or multi agentic AI, protecting against adversarial AI, secure software development for generative AI and risk management of dual-use foundation models, NIST aims to publish new guidance. Eventually, this can lead to new standards, regulations, and compliance requirements. Until then, we can brainstorm using first principles what types of risks multi-tenancy faces within AI infrastructure.
First, let’s separate training–at least for frontier models–from inference. In general, machine learning models train on humongous datasets to identify patterns. This is the big capital expenditure of the AI industry, whether the resulting model is for computer vision or language processing, and the output is a model with a trillion parameters locked in for a billion-dollar bill. I’m handwaving the numbers here because a commonly quoted figure like $100M to train GPT-5 probably accounts for only the final training run, none of the optimization runs that precede it. Every substantial update to frontier models can cost up to $1B just for the compute. With smaller models like domain-specialized models, obviously it would cost much less to train. “Is this a cat or a bicycle” is negligible compared to real-time vision processing for autonomous vehicles. Something like the latter likely requires dedicated GPU clusters. It’s safe to say, for arduous training tasks, single-tenancy is the way to go. For light training, such as fine-tuning an open-source model over a domain-specific dataset, and for inference, multi-tenancy works but with some risks.
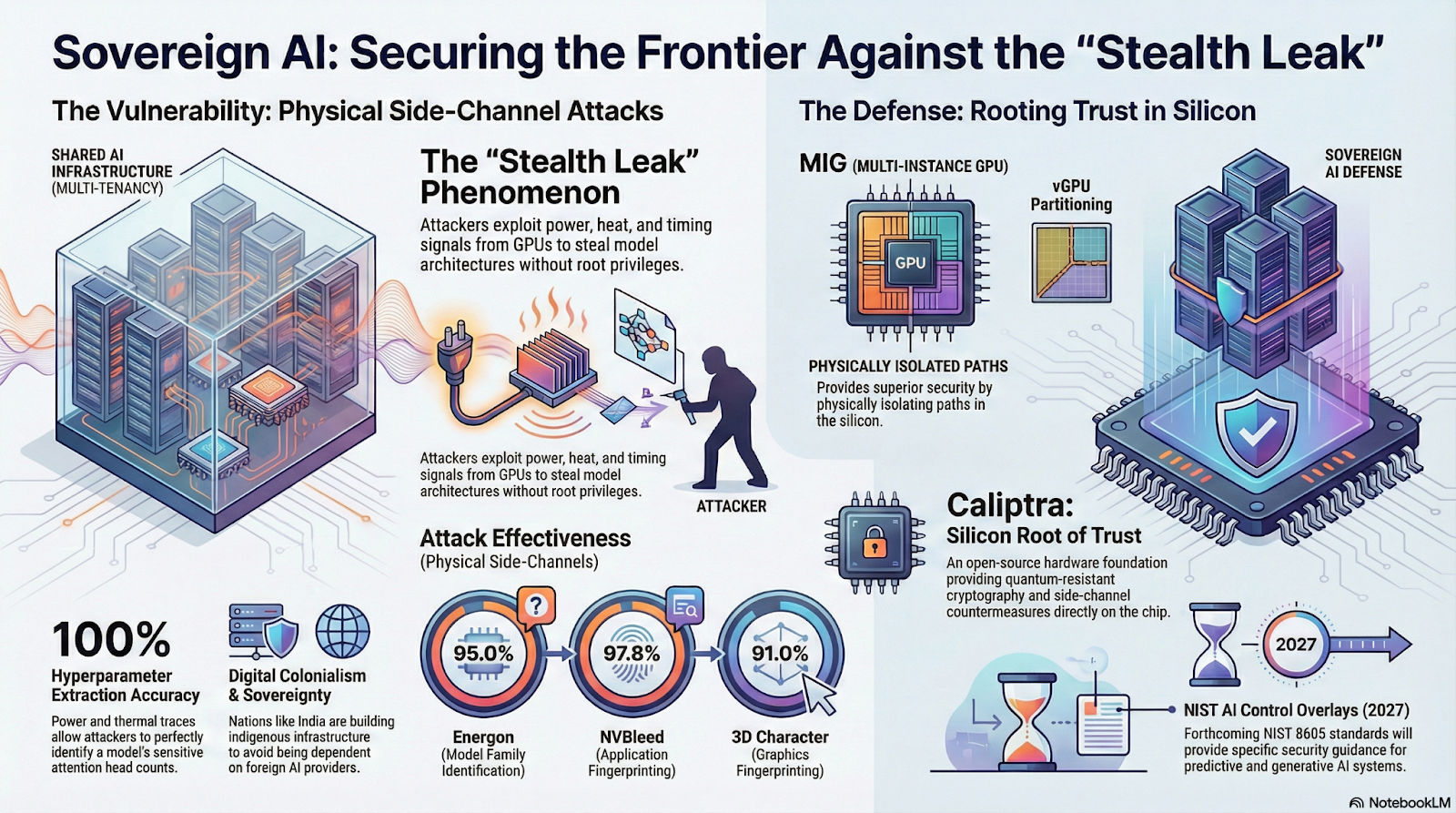
As stated earlier, logical separation is key in meeting the 800-53 requirements for a FedRAMP-authorized CSP; however, the hardware demand for AI complicates this, specifically the control SC-4, “Information in shared system resources.” In a more traditional IT infrastructure, this could be handled with a modern operating system or with virtual machines to ensure object reuse is impossible between users and tenants. With the parallel processing power of GPUs, logical separation isn’t enough because the same physical hardware may be used by multiple tenants, or else the hardware is underutilized. A software-driven virtualization like vGPU lets an entire GPU sequentially serve up to 48 virtual machines, but the hardware memory is now vulnerable to side-channel attacks. The Nvidia Multi-Instance GPU (MIG), as a hardware-driven virtualization, handles this much better with up to seven partitions, each with completely isolated paths in silicon as well as its own memory and cache resources. The attack surface shrinks considerably to interconnects and thermal power. It is a tradeoff: vGPU allows for greater parallel processing capacity by logically dividing the hardware in time, whereas MIG offers greater security by physically dividing the hardware in space.
Side-channel attacks are attracting much interest in the context of infrastructure security. I need to break this down a bit because it feels like something out of Mission Impossible. First, an attacker needs to map the infrastructure using latency probes and metadata scans to locate where GPU nodes are physically located. Then comes the hardest part: the attacker floods the cloud scheduler with dozens of instances with identical configurations as the target, hoping to be placed on the same hardware (which the scheduler considers efficient for identical instance requests). Next the attacker checks the pulse of the cache or interconnect to verify they are on the GPU of the target. Once on the hardware of the target, the attacker matches time, thermal, power, or cache pattern noise to a predetermined fingerprint library to discern the target’s architecture. Surely the attacker would train an AI beforehand to fingerprint these side channel effects from known models and hardware, if not buy a pretrained model from the dark web. It’s an unbelievably sophisticated attack, straight out of an international spy thriller, for the stakes are high. Successful side-channel attacks can reveal a model architecture, user inputs, even the model weights. That’s the secret sauce!
While the shift from vGPU to MIG does reduce the side-channel attack surface by separating the tenants’ cache resources, attackers can still exploit physical side channels while on the same host as the target. The NVBleed attack looks at timing and performance patterns in the high-speed interconnects between GPUs to indirectly discern traffic patterns from other virtual machines. The Energon attack similarly looks for performance patterns, specifically a power consumption staircase indicative of a transformer in inference, to reverse-engineer the layered architecture. Researchers have found both to be highly effective with over 90% accuracy in identifying model family and fingerprinting applications, 100% accuracy in extracting hyperparameters, and over 90% success in black-box attacks. Additionally, congestion on the PCIe bus, which MIG uses (without partitioning) to communicate to memory outside the GPU, can create a covert channel between isolated MIG instances. None of these attacks are easy to pull off, all depending on being on the same host, but they are real concerns for mutli-tenant AI infrastructure.
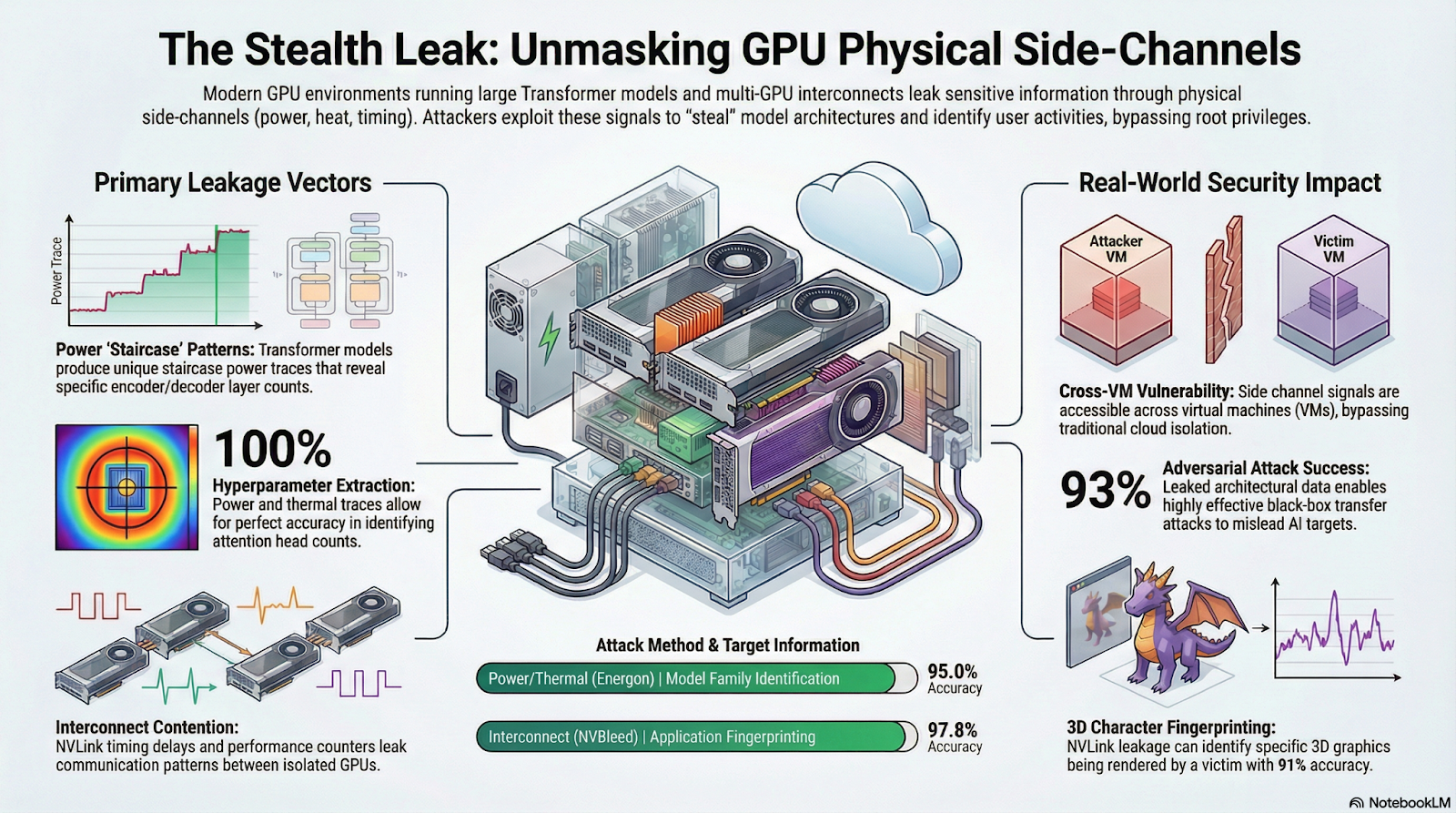
A hot new area where physical side-channel attacks attract interest is high-bandwidth memory (HBM). This is a 3-dimensional memory optimized with massive bandwidth and low latency to meet demands of GPUs in AI computing systems. To achieve this, a large-area silicon interposer directly (laterally, for now) connects the GPU to the stack of RAM; however, this also provides a thermal side–or rather, vertical–channel. Fundamentally, there is more thermal resistance in the vertical direction due to many more interfaces than in the planar direction. Layers that are further from the heat sink, typically closer to the interposer, retain heat longer. Not only could an attacker use thermal information to spy on the target’s workload a la Energon, they could also execute a denial-of-service by injecting heat into the target’s memory. This becomes especially concerning with HBM4, the latest generation of HBM which increasingly uses a fully vertical GPU-interposer-HBM stack in new designs. Cooling such a chip is already a technical hurdle without the added complication of a thermal attack. Plus a thermal attack could easily be disguised as a legitimate workload as the attacker isn’t even accessing any of the victim’s allocated memory. The 3D semiconductor engineering innovation that will advance the frontier of high-performance computing will introduce a new attack vector for catastrophic sabotage.
It takes being tricky to thwart the impossible. A CSP might intentionally introduce noise or timing inefficiencies for the sole purpose of preventing side-channel attacks, potentially to the chagrin of their customer. It might be well worth the tradeoff in performance to prevent advanced threat actors from stealing model weights or crashing training runs. One effective technique may be inserting noise. This needs to be done carefully as it could easily introduce performance issues which undermines the value of security. One option is temporal shuffling, wherein the order of execution is rescheduled at random where possible, preserving the total execution time while scrambling individual timing patterns. Another possibility is differential privacy, a mathematical technique to inject unpredictable, irreversible noise, which recently has been shifting from software to hardware for more security. The overhead cost to time, power, and performance can be mitigated slightly using the latest chip designs, such as Nvidia’s Rubin or Google’s Ironwood. By incorporating differential privacy into hardware design, noise injection can derive from on-chip thermal fluctuations. Thermal noise obfuscating thermal side channels!
The culmination of AI hardware security is the open-source Silicon Root of Trust, Caliptra. Backed by AMD, Nvidia, Microsoft, and Google, Caliptra ensures that the foundation of trust is built into the silicon hardware. Announced in October 2025, the latest Caliptra 2.1 incorporates Root of Trust with quantum-resistant cryptography, layered key management, and side channel countermeasures (Adam’s Bridge 2.0) on hardware. Nvidia’s Rubin and AMD’s Zen 6 are but two products that could bring Caliptra into data centers, establishing a rock-solid foundation in an AI Defense in Depth strategy. The fact that Caliptra is open-source means that any vendor can incorporate it into chip design, ensuring that trust is built into the AI infrastructure supply chain.
As NIST takes an active role in shaping US supply chain security standards, updates are in the works that are sure to influence future regulatory and compliance requirements. Three key pieces are the 800-218A, COSAiS, and Cyber AI Profile, each described as a profile/overlay onto the existing 800-218, 800-53, and Cybersecurity Framework (CSF). As mentioned earlier, SP 800-218A elaborates on the Secure Software Development Framework to address unique security risks while developing generative AI and dual-use foundation models. COSAiS (Control Overlays for Securing AI Systems) identifies specific 800-53 controls that require additional tailoring due to the intricacies of predictive, generative, and agentic systems. The Cyber AI Profile (NIST IR 8596) is the most strategic of the three, focusing on the intersection of AI and cybersecurity to help all organizations adopt AI as well as defend against AI-based attacks.
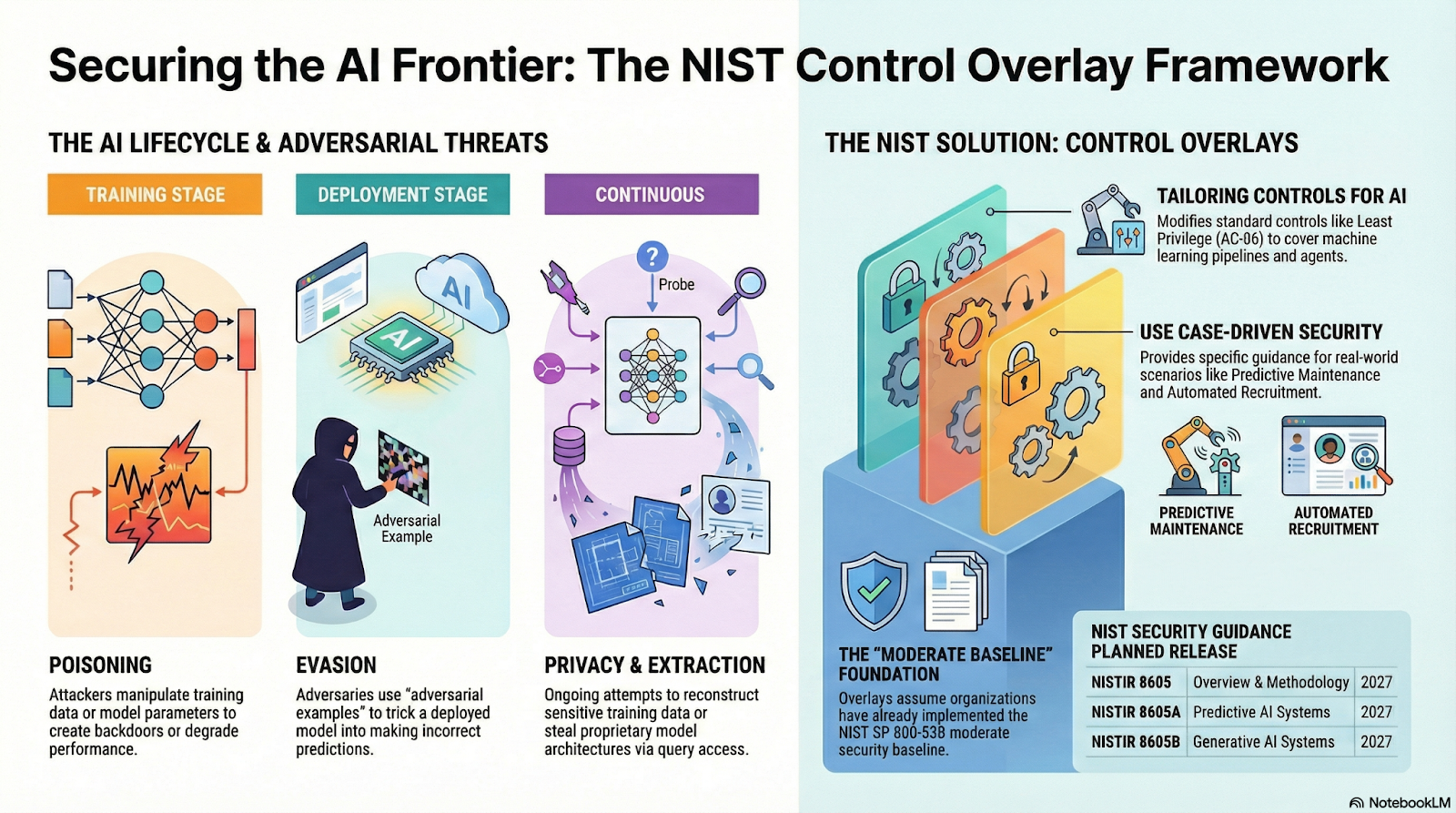
In terms of topics previously discussed, COSAiS expands baseline configuration and impact analysis requirements to consider infrastructure components and dynamic compute resources. For a CSP that already meets the FedRAMP Moderate baseline, there could be additional requirements to consider model exfiltration in risk assessment and boundary protection, as well as physical and environmental modeling. As of January 2026, however, none of these documents shine light on the specific hardware security and integrity vulnerabilities we discussed. Hence, Caliptra fills a gap that is yet unfilled in the US regulatory environment, at least for now. In the bigger picture, it is completely reasonable to expect standards and requirements to address AI hardware security.
Artificial intelligence is driving an unprecedented infrastructure buildout worldwide with geopolitical and cybersecurity implications. Specialized semiconductor technology introduces the risk of advanced threat actors employing physics-based attacks in multi-tenant cloud services to steal billion-dollar intellectual property, while also raising questions of sovereignty among states seeking independence from foreign infrastructure providers. India provides a fascinating example playing out before our eyes. A security governance suite including Caliptra for Root of Trust and novel standards that go beyond NIST’s current drafts will prove critical to securing AI down to the material level. Combine AI sovereignty with AI security and the result is a bold step in the direction of indigenous AI autonomy, the end of digital colonialism.
Reference dump:
https://csrc.nist.gov/pubs/sp/800/218/a/final
https://csrc.nist.gov/projects/cosais
https://www.nccoe.nist.gov/projects/cyber-ai-profile
https://arxiv.org/abs/2508.01768
https://arxiv.org/abs/2503.17847
https://arxiv.org/abs/2509.00633v1
https://www.vmware.com/docs/vgpu-vs-mig-perf
https://indiaai.gov.in/hub/indiaai-compute-capacity
https://docs.nvidia.com/datacenter/tesla/mig-user-guide/introduction.html
https://en.datasumi.com/the-trillion-parameter-price-tag-a-definitive-economic-analysis-of-gpt-5
https://www.forbes.com/sites/katharinabuchholz/2024/08/23/the-extreme-cost-of-training-ai-models/
https://mpost.io/gpt-5-training-will-cost-2-5-billion-and-start-next-year/

